During developing a dispatch table for some instructions in binaries, one of the challenging problem which I faced, was changing the registers state in a way that doesn’t affect the program flow!
So it might seem simple at first glance but what makes it complex is that I can’t use relative jumps or relative calls because, in some situation, I might be far away from .text segment of my binary.
It causes me to explore the solutions about far jumps and far calls but actually, I realized that it can’t help me too.
One of the solutions was to put the final address in the stack, then use ret in order to change xip (rip or eip).
1
2
push 0xdeadbeef
ret
It is somehow a good solution, its fast and is really recommended, but the thing is I don’t want to change the stack state either! Even one of my friends told me that changing the above addresses of the stack doesn’t affect a regular compiler’s flow but I think it might be better, not to modify stack because I want to publish its source and it might cause the problem in abnormal programs in future.
And of course another solution was using registers like :
1
2
mov %eax,0xdeadbeef
jmp %eax
It’s clear that it causes nasty problems because the rest of program flow don’t know about %eax changes so it uses a wrong value and we can’t do any further modification.
Solution
I solved the above problem by using the following code, in at&t syntax (in x86):
1
2
jmp *0f(%eip)
0: .int 0x12345678
The above instruction, jumps to 0x12345678 in x86 and you can see the result of compiling and disassembling it :
1
Sinas-MBP:Desktop sina$ clang -c aa.asm -m32
And to Dissemble it using objdump use the following format :
1
2
3
4
5
6
7
8
9
Sinas-MBP:Desktop sina$ objdump -d aa.o
aa.o: file format Mach-O 32-bit i386
Disassembly of section __TEXT,__text:
__text:
0: ff 25 00 00 00 00 jmpl *0
6: 78 56 js 86 <__text+0x5E>
8: 34 12 xorb $18, %al
In the case of x64 version of above code you can use the rip instead of eip and change the int to quad because you need more space for x64 addressing.
1
2
jmp *0f(%rip)
0: .quad 0x1234567890
1
Sinas-MBP:Desktop sina$ clang -c aa.asm
To Dissemble it using objdump use the following format :
1
2
3
4
5
6
7
8
9
10
11
12
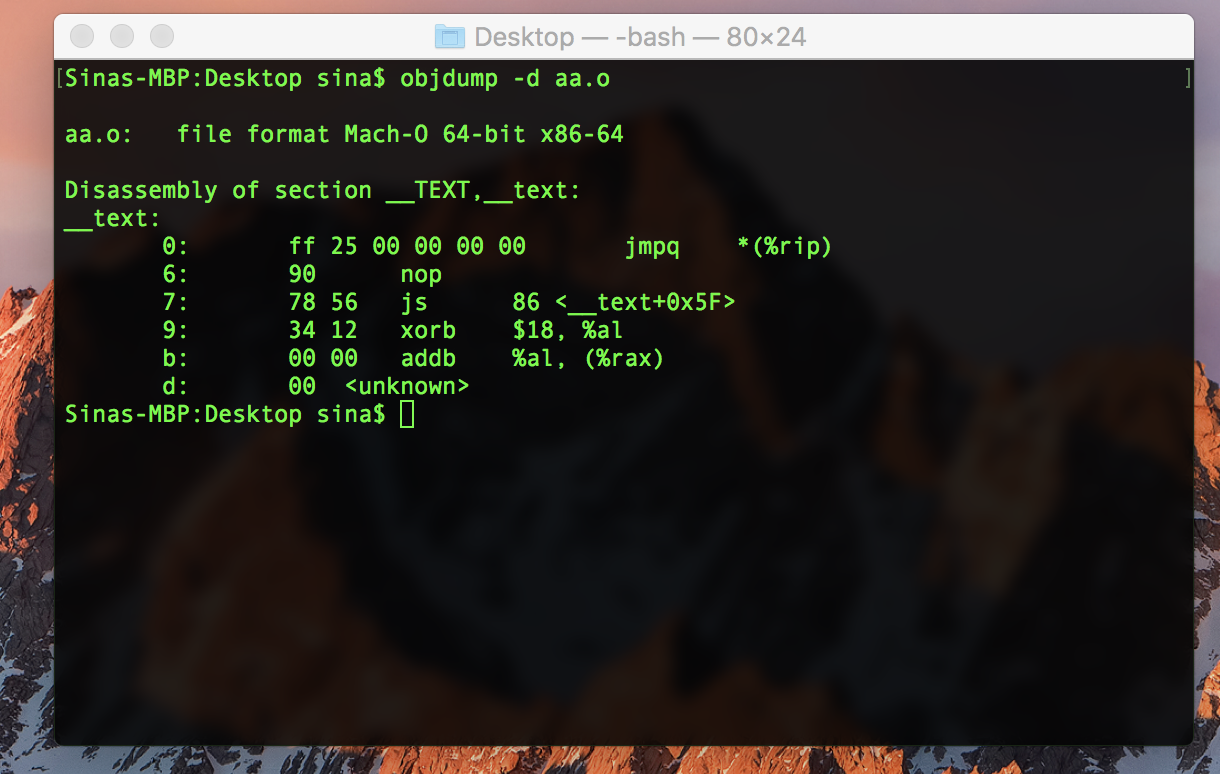
Sinas-MBP:Desktop sina$ objdump -d aa.o
aa.o: file format Mach-O 64-bit x86-64
Disassembly of section __TEXT,__text:
__text:
0: ff 25 00 00 00 00 jmpq *(%rip)
6: 90 nop
7: 78 56 js 86 <__text+0x5F>
9: 34 12 xorb $18, %al
b: 00 00 addb %al, (%rax)
d: 00
The above code jumps to 0x1234567890.
The Problem Of Relative Conditional Jumps
By now, you might think of implementing the above jmp for j* instruction like je or jnb , but the thing is you can’t because we don’t have a conditional instruction to perform the above command.
So how can we solve this ?
Simply, use relative conditional jumps with a combination of above jmp, so that the conditional jump can do what it expects to base on the flags and then it can decide to jump over an instruction (in our case jump to a far address) or can perform the above jmp.
1
2
3
4
5
# for jz addr
jnz 1f
jmp *0f(%rip)
0: .quad addr
1:
Final Thoughts
The above post derived from my question in stack overflow here, which finally answered by fuz. Even if this solution solves my problem but it is not really a good and fast way to perform this jump, and Intel advice not to use such instructions because they are really slow in CPU clock execution cycles and because I should use these instructions billions of time in a simple binary, then the normal execution becomes much slower than what I expect. So If you have any better solution, then let me know about it.
Comments powered by Disqus.